
ქართული
Allgemein
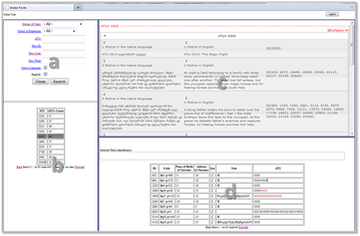
Der EPdVE stellt ein Internetdatensystem für außenstehenden und privilegierten Anwender dar. Das System wird mit zwei Einsatzfunktionen aufgerüstet: Abfrage- und Eingabevorgänge. Die erste Funktion ist für alle zugänglich, die Anwendung der zweite Funktion der Datenbank ist hingegen nur für die privilegierte Benutzer verfügbar.
Das Programm EPdVE besteht aus folgenden Bereichen (s. Abb.1):
- Suchmaschine (a)
- Tabelle zur quantitativen Angaben der ATU Typen (b)
- Motivbestand der ATU Typen (c)
- Angaben zu den Texte (d)
Abb. 1. EPdVE im Einsatz
Suchmaschine (a)
Die Suchmaschine enthält folgende Suchfelder:
- Gruppe der Anwender. Durch dieseSuchfunktion ist es möglich die Datenbestand nach Anteil der einzelnen Projekt-Beteiligter bzw. Instituten einzeln abzuruffen. Jeder privilegierte Anwender gehört zu einer bestimmten Gruppe. Bei dem Eingabevorgang darf der Vertreter der jeglichen Gruppe nur seinen eigenen Datenbestand bearbeiten, d.h. die Funktion des Feldes besteht darin die Intervention von Aussen zu verhindert.
- Herkunft des Repertoires. Durch dieses Feld ist es möglich die Materialien nach ihrer ethnischen Herkunft zu sortiert.
- ATU - Typennummer. Durch dieses Feld ist es möglich das Bild des Typenbestandes jedes in der Datenbank eingetragenes Materials nach ihre Herkunft und geographische Verbreitung zu betrachten. Derzeit enthält die Datenbank nach dem Internationale Aarne-Thompson-Uther Katalog bearbeitete Daten (s.The Types of International Folktales. A Classifikation and Bibliography. Based on the System of Antti Aarne and Stith Thopson. By Hans-Jörg Uther. Helsinki 2004). Es gibt keine prinzipiele Einschränkung die verhindern konnte die Texten nach anderem Klasifikationssystem zu beschreiben.
- Identifikationsnummer des Textes in der Datenbank. Jeder Text in Datenbank hat seine unikale Nummer. Durch die Eingabe der Nummer ins Suchfeld wird der Motivbestand des einzelnen Textes abzurufen.
- Textcode. Archivsignatur des Textes.
- Stichwort. Das Feld bezieht sich auf den Wortschatz die bei der Motivbeschreibung enteht.
- Ein- und Ausschalter der Beschreibung des Types ins Nativen und ins Englischen
Tabelle mit der quantitativen Angaben zu den ATU Typen (b)
- Diese Tabelle ethält die Information über die Häufigkeit der Typen im abrufbare Repertoire.
- Mit dem Nul-Index sind die übrigen, nicht zu dem Erzählforschung geeignete Texte bezeichnet.
- Durch das Doppelklick auf die Überschrift der Tabelle ATU oder ATUs Count ist es möglich die angaben in belibiege Reihefolge, von A bis Z oder umgekehrt einzuordnen.
- Nach dem Abruf der Angaben in der Tabelle wird die erste Zeile automatisch aktualisiert.
- Durch den einmaligen Klick ist es möglich beliebige Zeile in der Tabelle zu aktivieren.
Motivbestand des ATU Typs (c)
- Das Bereich stellt ein flexiebles System der inhaltlichen Elemente des ATU Typs dar.
- Die Flexibilitä des Systems besteht in der Möglichkeit während der Aufbau bzw. Ergänzung des Motivbestandes einzelne Motive von Ort zu Ort zu schieben, löschen oder in die vorhandene Reihenfolge ein alterniertes Motiv einzutragen (falls das Motiv fehlt oder als Varianz auftritt).
- Neben der Motivbeschreschreibung stehen die Identifikationsnummer derjenigen Texten in denen das beschriebene Motiv auftritt.
- Durch diesen Bereich des Programms verfügt man über ein vollständiges Bild der Variantion des Typs;
- Anhand der Angaben zur Häufigkeit der Varianten der einzelnen Motive ist es möglich, den relevanten Motivbestand des Typs festzustellen.
Textangaben (d)
Hier sind folgende Angaben über den Text bzw. die Texten zu Verfügung gestellt:
Durch den einmaligen Klick auf die einzelnen Zeile ist es möglich entsprechender Textdatei abzurufen.
- ID Nummer,
- Information zu den Wohn- und Geburtsort des Erzählers / der Erzählerin,
- zum Geschlecht des Erzählers / der Erzählerin,
- Bemerkungen zum Text,
- ATU Index ggf. Kombination der Indexen.
Durch den einmaligen Klick auf die einzelnen Zeile ist es möglich entsprechender Textdatei abzurufen.
